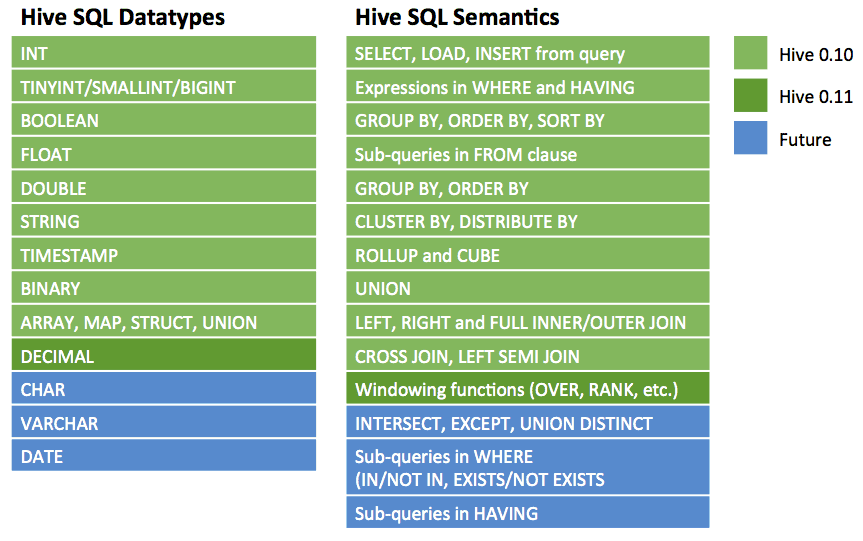
From a querying perspective, using Apache Hive provides a familiar interface to data held in a Hadoop cluster and is a great way to get started. Apache Hive is data warehouse infrastructure built on top of Apache Hadoop for providing data summarization, ad-hoc query, and analysis of large datasets. It provides a mechanism to project structure onto the data in Hadoop and to query that data using a SQL-like language called HiveQL (HQL).
Naturally, there are a bunch of differences between SQL and HiveQL, but on the other hand there are a lot of similarities too, and recent releases of Hive bring that SQL-92 compatibility closer still.
Read more here